
La méthode Python where dans les formules Excel
")





Pour partager cette vidéo sur les réseaux sociaux ou sur un site, voici son url :







La méthode Python Where
La méthode where en Python permet d'appliquer des conditions sur des DataFrames représentant des tableaux Excel. Cette méthode est très puissante pour effectuer des opérations conditionnelles sur des données. Elle permet de filtrer des informations sur des critères recoupés, un peu comme la méthode Python query mais en plus simple.
Classeur Excel à télécharger
Nous suggérons d'expérimenter cette méthode where sur un classeur Excel existant.
- Télécharger le classeur methode-where-python.xlsx en cliquant sur ce lien,
- Double cliquer sur le fichier réceptionné pour l'ouvrir dans Excel,
- Puis, cliquer sur le bouton Activer la modification dans le bandeau de sécurité,
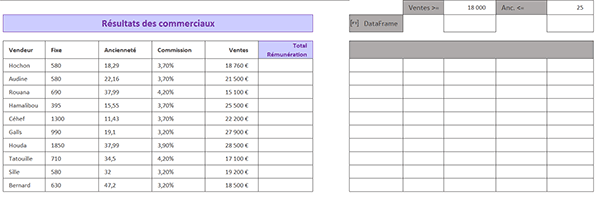
Nous travaillons à partir d'un tableau des ventes entre les colonnes B et G. Nous l'avons encapsulé dans un DataFrame Python en cellule I3 : tab=xl("B5:F15", headers=True).
Les critères
Nous émettons deux critères sur les ventes à dépasser en K2 et sur l'ancienneté à ne pas atteindre en M2. Nous devons les encapsuler dans deux objets Python en cellules respectives K3 et M3.
- Cliquer sur la cellule K3 sous le premier critère pour la sélectionner,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Débuter la syntaxe comme suit : cr1=,
- Dès lors, cliquer sur la case du premier critère, ce qui donne : cr1=xl("K2"),
- Valider la création par le raccourci clavier CTRL + Entrée,
- Cliquer sur la cellule M3 sous le second critère pour la sélectionner,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Débuter la syntaxe comme suit : cr2=,
- Cliquer sur la case du second critère, ce qui donne : cr2=xl("M2"),
- Valider la création par le raccourci clavier CTRL + Entrée,
Extraire sur critères recoupés
En cellule I5, nous devons recouper ces critères sur la colonne des ventes et sur celle des anciennetés.
- Cliquer sur la cellule I5 pour la sélectionner,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Puis, débuter la syntaxe comme suit : tab = tab,
- Taper un point (.) pour appeler la méthode pour recouper les conditions,
- Inscrire cette méthode suivie de deux parenthèses ouvrantes, soit : where((,
- Emettre la première condition sur la colonne des ventes, comme suit : tab['Ventes']>= cr1),
- Inscrire le symbole de concaténation (&) pour annoncer le second critère à recouper,
- Emettre cette seconde condition sur la colonne des anciennetés : (tab['Ancienneté']<= cr2),
- Fermer la deuxième parenthèse,
- Puis, valider la formule par le raccourci clavier CTRL + Entrée,
- A gauche de la barre de formule, cliquer sur la flèche puis choisir Valeur Excel,
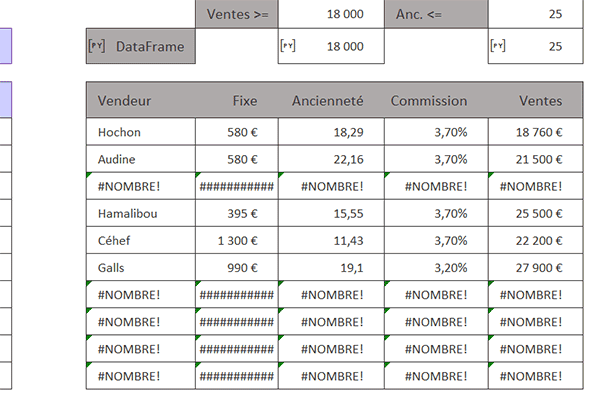
Au milieu d'innombrables erreurs, nous obtenons bien la liste des personnes satisfaisant aux deux conditions.
Supprimer les lignes réfractaires
Mais nous le savons, au travers de tous les sujets que nous avons déroulés ensemble, il existe une méthode Python permettant d'éliminer, d'un coup de baguette magique, toutes les lignes portant des erreurs. Cette méthode se nomme dropna.
- Cliquer de nouveau sur la cellule I5 pour activer la case de la formule,
- Dans la barre de formule, cliquer à la toute fin de la syntaxe pour y placer le point d'insertion,
- Appeler en cascade la méthode dropna comme suit :
- Valider alors l'adaptation par le raccourci clavier CTRL + Entrée,
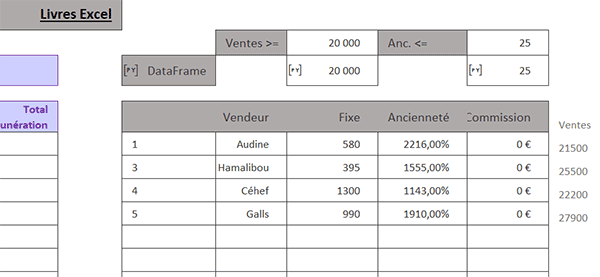
Comme vous le constatez, toutes les erreurs disparaissent et seules subsistent les lignes satisfaisant les deux critères. Bien sûr, si vous veniez à modifier l'un ou l'autre levier en K2 ou M2, l'extraction s'actualiserait aussitôt.
Supprimer la colonne des index
Bien sûr et cela ne vous a sans doute pas échappé, une colonne résiduelle s'invite. Elle renseigne sur les index, c'est-à-dire sur les positions de ces lignes extraites depuis le tableau d'origine. Nous ne souhaitons pas voir apparaître ces informations. Et comme nous l'avons déjà appris, c'est la méthode reset_index qui permet de l'éliminer.
- Cliquer de nouveau sur la cellule I5 pour activer la case de la formule,
- Dans la barre de formule, cliquer à la toute fin de la syntaxe pour y placer le point d'insertion,
- Appeler la méthode Python reset_index comme suit :
Cette fois l'extraction est parfaitement réalisée sur la base de ces deux critères recoupés et s'ajuste immédiatement au moindre changement de l'une ou l'autre contrainte.
Sur Facebook

Sur Youtube

Les livres

Contact

Mentions légales







